Create A Simple Web Crawler in php
- Digital Engineering
Create A Simple Web Crawler in php
A Web Crawler is a program that crawls through the sites in the Web and find URL’s. Normally Search Engines uses a crawler to find URL’s on the Web. Google uses a crawler written in Python. There are some other search engines that uses different types of crawlers.
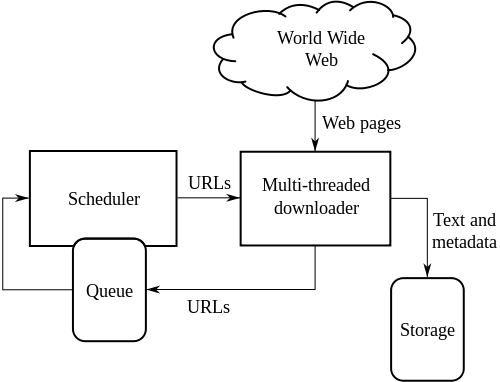
For Web crawling we have to perform following steps-
1.Firstly make url of page which we have to crawl.
2.Then we have to fetch link of that particular website.Following curl () function fetches link of website–
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
function curl($url) { // Assigning cURL options to an array $options = Array( CURLOPT_RETURNTRANSFER => TRUE, // Setting cURL's option to return the webpage data CURLOPT_FOLLOWLOCATION => TRUE, // Setting cURL to follow 'location' HTTP headers CURLOPT_AUTOREFERER => TRUE, // Automatically set the referer where following 'location' HTTP headers CURLOPT_HEADER=> TRUE, CURLOPT_CONNECTTIMEOUT => 1200, // Setting the amount of time (in seconds) before the request times out CURLOPT_TIMEOUT => 1200, // Setting the maximum amount of time for cURL to execute queries CURLOPT_MAXREDIRS => 10, // Setting the maximum number of redirections to follow CURLOPT_USERAGENT => "Googlebot/2.1 (+http://www.googlebot.com/bot.html)", // Setting the useragent CURLOPT_URL => $url, // Setting cURL's URL option with the $url variable passed into the function CURLOPT_ENCODING=>'gzip,deflate', ); $ch = curl_init(); // Initialising cURL curl_setopt_array($ch, $options); // Setting cURL's options using the previously assigned array data in $options $data = curl_exec($ch); // Executing the cURL request and assigning the returned data to the $data variable $httpcode = curl_getinfo($ch, CURLINFO_HTTP_CODE);//to check whether any error occur or not if($httpcode!="200") { return "error"; } return $data; // Returning the data from the function } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
function crawl($html) { $dom->loadHTML($html); $content = $dom->getElementsByTagname('a'); foreach ($content as $item) { echo $item->getAttribute('href'); } } 4.Finally we will call $results_page=curl($url); crawl($results_page); |