Horizontal Pod Autoscaling
- DevOps
Horizontal Pod Autoscaling
Autoscaling is one of the key features in the Kubernetes cluster. It is a feature in which the cluster is capable of increasing the number of pods/nodes as the demand for service response increases and decreases the number of pod/nodes as the requirement decreases.
Types of Autoscaling
Kubernetes Autoscaling mechanisms help scale in and out pods and nodes as required. There are three different methods supported by Kubernetes Autoscaling.
- Horizontal Pod Autoscaler (HPA)
- Vertical Pod Autoscaler (VPA)
- Cluster Autoscaler (CA)
Horizontal Pod Autoscaler (HPA)
A Kubernetes functionality to scale out (increase) or scale in (decrease) the number of pod replicas automatically based on defined metrics.
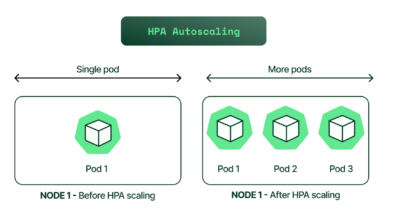
How Does Horizontal Pod Autoscaling Work?
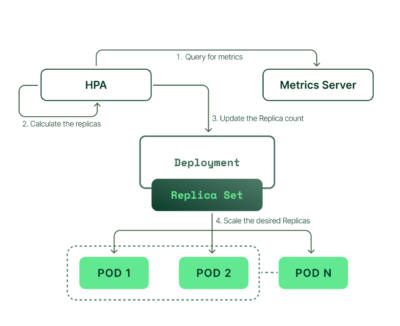
- HPA continuously monitors the metrics server for resource usage.
- Based on the collected resource usage, HPA will calculate the desired number of replicas required.
- Then, HPA decides to scale up the application to the desired number of replicas.
- Finally, HPA changes the desired number of replicas.
- Since HPA is continuously monitoring, the process repeats from Step 1.
The default interval for HPA checks is 30 seconds. Use the --horizontal-pod-autoscaler-sync-period controller manager flag to change the interval value.

- Autoscaling/v1: This is the stable version available with most clusters. It only supports scaling by monitoring CPU usage against given CPU thresholds.
- Autoscaling/v2beta1: This beta version supports both CPU and memory thresholds for scaling. This has been deprecated in Kubernetes version 1.19.
Autoscaling/v2beta2: This is the beta version that supports CPU, memory, and external metric thresholds for scaling. This is the recommended API to use if you need autoscaling support for metrics other than CPU utilization
Prerequisites
Metrics Server. This needs to be setup if you are using kubeadm etc. and replaces heapsterstarting with kubernetes version 1.8.
Resource Requests and Limits. Defining CPUas well as Memoryrequirements for containers in Pod Spec is a must
Deploying Metrics Server
Kubernetes Horizontal Pod Autoscaler along with kubectl top command depends on the core monitoring data such as cpu and memory utilization which is scraped and provided by kubelet, which comes with in built cadvisor component. Earlier, you would have to install a additional component called heapster in order to collect this data and feed it to the hpa controller. With 1.8 version of Kubernetes, this behavior is changed, and now metrics-server would provide this data. Metric server is being included as a essential component for kubernetes cluster, and being incroporated into kubernetes to be included out of box. It stores the core monitoring information using in-memory data store.
Clone metric server repo and deploy
Clone : git clone https://github.com/kubernetes-incubator/metrics-server.git
Switch : cd metrics-server
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml

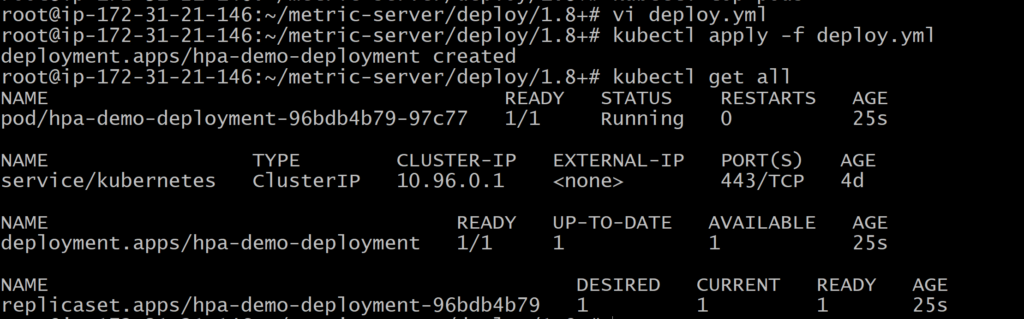
Deploy Sample Applicatoin
deploy.yml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
apiVersion: apps/v1 kind: Deployment metadata: name: hpa-demo-deployment spec: selector: matchLabels: run: hpa-demo-deployment replicas: 1 template: metadata: labels: run: hpa-demo-deployment spec: containers: - name: hpa-demo-deployment image: k8s.gcr.io/hpa-example ports: - containerPort: 80 resources: limits: cpu: 500m requests: cpu: 200m |
Create the Kubernetes service
Service.yml
|
1 2 3 4 5 6 7 8 9 10 11 |
apiVersion: v1 kind: Service metadata: name: hpa-demo-deployment labels: run: hpa-demo-deployment spec: ports: - port: 80 selector: run: hpa-demo-deployment |

Install the Horizontal Pod Autoscaler
Hpa.yml
|
1 2 3 4 5 6 7 8 9 10 11 12 |
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: hpa-demo-deployment spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: hpa-demo-deployment minReplicas: 1 maxReplicas: 10 targetCPUUtilizationPercentage: 50 |

Check the Load on Pods

Increase the load
Once you triggered the load test, use the below command, which will show the status of the HPA every 30 seconds:

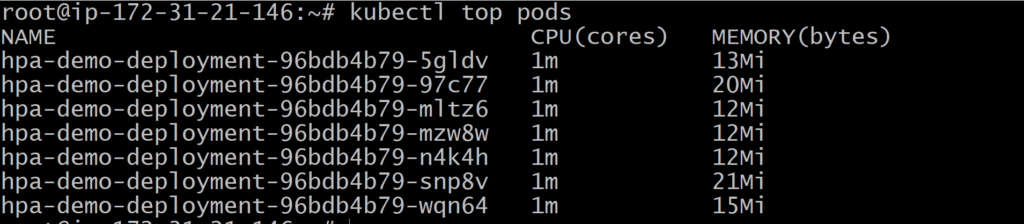
you can see that as our usage went up, the number of pods scaled from 1 to 5 also see pod usage metrics. The load-generator pod generates the load for this example
Decrease the load
we’ll decrease the load. Navigate to the terminal where you executed the load test and stop the load generation by entering + C.
we can observer load lifting from the pods
Here load lifted , deployment back to normal state

The following is an example of scaling a deployment by CPU and memory. For CPU, the average utilization of 50% is taken as the target, and for memory, an average usage value of 500 Mi is taken. In addition, there is an object metric that monitors the incoming requests per second in ingress and scales the application accordingly.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
apiVersion: autoscaling/v2beta2 kind: HorizontalPodAutoscaler metadata: name: sample-app-hpa namespace: default spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: sample-app minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 50 - type: Resource resource: name: memory target: type: AverageValue averageValue: 500Mi - type: Object object: metric: name: requests-per-second describedObject: apiVersion: networking.k8s.io/v1beta1 kind: Ingress name: main-route target: type: Value value: 10k |
Kubernetes custom metrics
autoscaling/v2 API version, you can configure a HorizontalPodAutoscaler to scale based on a custom metric (that is not built in to Kubernetes or any Kubernetes component). The HorizontalPodAutoscaler controller then queries for these custom metrics from the Kubernetes API.
Links for reference:
https://towardsdatascience.com/kubernetes-hpa-with-custom-metrics-from-prometheus-9ffc201991e
Best Practices
When running production workloads with autoscaling enabled, there are a few best practices to keep in mind.
Install a metric server:Kubernetes requires a metrics server be installed in order for autoscaling to work. The metrics server enables the Kubernetes metric APIs, which the autoscaling algorithms utilize, to make scaling decisions.
Define pod requests and limits:A Kubernetes scheduler makes scheduling decisions according to the requests and limits set in the pod. If not set properly, Kubernetes will be unable to make an informed scheduling decision, and pods will not go into a pending state due to lack of resources. Instead, they will go into a CrashLoopBackOff, and Cluster Autoscaler won’t kick in to scale the nodes. Furthermore, with HPA, if initial requests are not set to retrieve the current utilization percentages, scaling decisions will not have a proper base to match resource utilization policies as a percentage.
Specify PodDisruptionBudgets for mission-critical applications:PodDisruptionBudget avoids disruption of critical pods running in the Kubernetes Cluster. When a PodDisruptionBudget is defined for a certain application, autoscaler will avoid scaling down replicas beyond the minimum value configured in the disruption budget.
Resource requests should be close to the average usage of the pods: Sometimes an appropriate resource request can be hard to determine for new applications, as they have no previous resource utilization data. However, with Vertical Pod Autoscaler, you can easily run it in recommendation mode. Recommendations for the best values for CPU and memory requests for your pods are based on short-term observations of your application’s usage.
Increase CPU limits for slow starting applications: Some applications (ex: Java Spring) require an initial CPU burst to get the application up and running. At runtime the application would typically use a small amount of CPU compared to the initial load. To mitigate this, it is recommended to limit CPU to a higher level. This will allow these containers to start up quickly and to add lower request levels that match the typical runtime request usage of these applications.
Don’t mix HPA with VPA:Horizontal Pod Autoscaler and Vertical Pod Autoscaler should not be run together. It is recommended to run Vertical Pod Autoscaler first, to get the proper values for CPU and memory as recommendations, and then to run HPA to handle traffic spikes.