How to increase accuracy of Tesseract
- Data, AI & Analytics
- Digital Engineering
How to increase accuracy of Tesseract
Accuracy of Tesseract OCR in Java
What is OCR?
OCR stands for “Optical Character Recognition”. It is a technology that recognizes text within a image. It is commonly used to recognize text in scanned documents and images. OCR software can be used to convert a physical paper document, or an image into an accessible electronic version with text.
Why OCR?
Optical character recognition (OCR) technology is a business solution for automating data extraction from printed or written text from a scanned document or image file and then converting the text into a machine-readable form to be used for data processing like editing or searching.
What is Tesseract OCR?
Tesseract OCR is an optical character reading engine developed by HP laboratories in 1985 and open sourced in 2005. Since 2006 it is developed by Google.
Tesseract has Unicode (UTF-8) support and can recognize more than 100 languages “out of the box” and thus can be used for building different language scanning software also. Latest Tesseract version is Tesseract 4.
It adds a new neural net (LSTM) based OCR engine which is focused on line recognition but also still supports the legacy Tesseract OCR engine which works by recognizing character patterns.
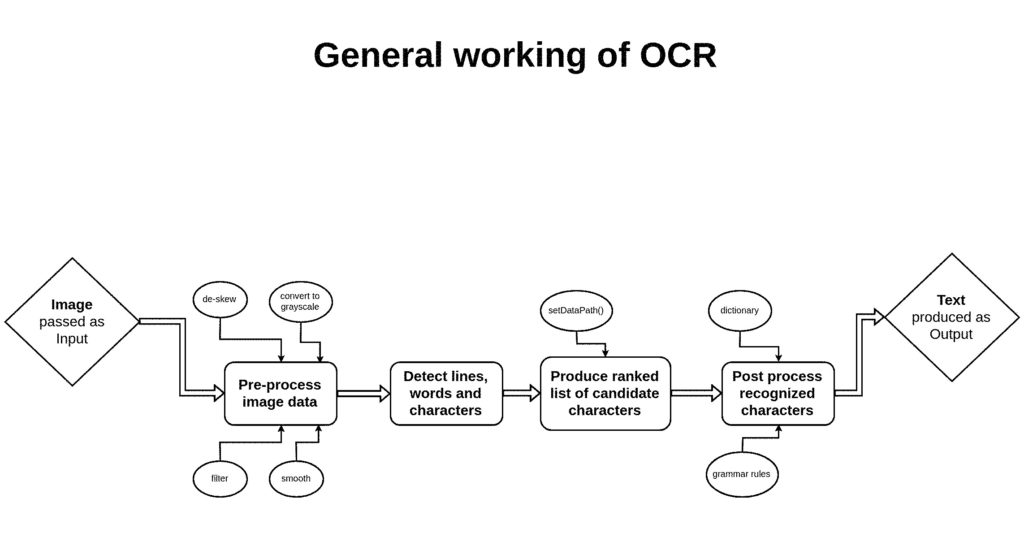
Working of OCR?
Generally OCR works as follows:
- Preprocess image data, for example: convert to gray scale, smooth, de-skew, filter.
- Detect lines, words and characters.
- Produce ranked list of candidate characters based on trained data set. (here the setDataPath() method is used for setting path of trainer data)
- Post process recognized characters, choose best characters based on confidence from previous step and language data. Language data includes dictionary, grammar rules, etc.
OCR accuracy on Unclear image.
In most of the cases, we get a noisy image and thus we get a very noisy output. To deal with it we need to perform some processing on the image called Image processing.
Tesseract perform implicit image processing by default, but it is not enough to obtain high accuracy on a noisy image.
That’s why we need to perform some explicit image processing techniques such as
- fix DPI (if needed) 300 DPI is minimum
- fix text size (e.g. 12 pt should be ok)
- try to fix text lines (de-skew and de-warp text)
- try to fix illumination of image (e.g. no dark part of image)
- Convert an image into gray scale.
- Binarize (Gray Scaled) and de-noise image.
1. Scaling of image to right size
For better accuracy images are scaled at least 300 DPI(Dots Per Inch). Keeping DPI lower than 200 will give unclear and incomprehensible results while keeping the DPI above 600 will unnecessarily increase the size of the output file without improving the quality of the file. Thus, a DPI of 300 works best for this purpose.
|
1 2 |
Tesseract it = new Tesseract(); it.setTessVariable("user_defined_dpi", "300"); |
2. Increasing contrast of image
Low contrast can result in poor OCR.Increasing the contrast between the text/image and its background brings out more clarity in the output.
3. Image Binarization
It is a process of converting an gray-scaled image to black and white image.
Getting the RGB content of image
|
1 2 3 |
double d = ipimage .getRGB(ipimage.getTileWidth() / 2, ipimage.getTileHeight() / 2); |
Creating a 2D platform on the buffer image for drawing the new image
|
1 2 |
BufferedImage outputImage = new BufferedImage(1050,1024,ipimage.getType()); Graphics2D graphic = outputImage.createGraphics(); |
Drawing new image starting from 0 ,0 of size 1050 x 1024 (zoomed images) and null is the Image Observer class object
|
1 2 |
graphic.drawImage(inputImage, 0, 0,1050, 1024, null); graphic.dispose(); |
Now using RescaleOp object for gray scaling images
|
1 2 3 |
RescaleOp rescale = new RescaleOp(scaleFactor, offset, null); BufferedImage fopimage = rescale.filter(opimage, null); ImageIO.write(fopimage, "IMAGE_FILE_TYPE", new File("OUTPUT_IMAGE_FILE_PATH")); |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
public static BufferedImage RGBToGrayScale(BufferedImage file) throws IOException { BufferedImage image; int width; int height; File output = new File("FILE_PATH"); try { image = file; width = image.getWidth(); height = image.getHeight(); for (int i = 0; i < height; i++) { for (int j = 0; j < width; j++) { Color c = new Color(image.getRGB(j, i)); int red = (int) (c.getRed() * 0.299); int green = (int) (c.getGreen() * 0.587); int blue = (int) (c.getBlue() * 0.114); Color newColor = new Color(red + green + blue, red + green + blue, red + green + blue); image.setRGB(j, i, newColor.getRGB()); } } ImageIO.write(image, "jpg", output); } catch (Exception e) { } return ImageIO.read(output); } |
4. Remove Noise
Noise can drastically reduce the overall quality of the OCR process. It can be present in the background or foreground and can result from poor scanning or the poor original quality of the data.
5. De-skewing of image
De-skewing can be referred to as rotation. This means de-skewing the image to bring it in the right format and right shape. The text should appear horizontal and not tilted in any angle. If the image is skewed to any side, de-skew it by rotating it clockwise or anti clockwise direction.
6. Set Tesseract engine to read particular characters only
|
1 |
it.setTessVariable("tessedit_char_whitelist","0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz/' '"); |