Context Based QnA Using Google’s State Of Art -PreTrained BERT
- General
Context Based QnA Using Google’s State Of Art -PreTrained BERT
Why Transformers?
The problems with long-existing sequence models are long-range dependencies, vanishing and exploding gradient is hard to resolve even batch gradient descent when network is large and deep, a large amount of training steps needed, as well as recurrence prevent from parallel execution for which we aren’t able to use GPUs for fast processing. In a research paper published in 2017 named “ATTENTION IS ALL YOU NEED” by dr. Vaswani and his team working at Google Brain, they proposed a ‘Transformer’ model which solves all problems posed by recurrent networks.
Here is a representation of a transformer unit-
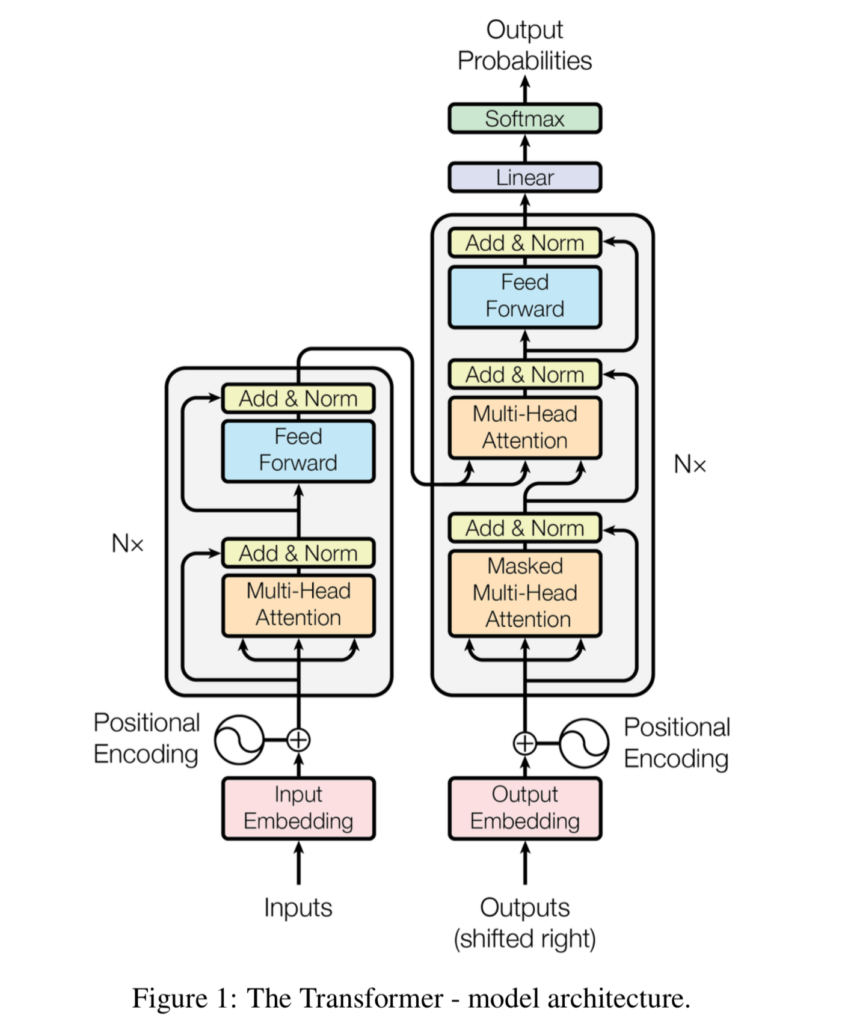
Model Architecture: this neural network has an encoder-decoder architecture Here, the encoder maps an input sequence of symbol representations (x1,…,xn) to a sequence of continuous representations z = (z1,…,zn). Given z, the decoder then generates an output sequence (y1, …, ym) of symbols one element at a time. At each step the model is auto-regressive, consuming the previously generated symbols as additional input when generating the next.
Attention Mechanism: An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
Unlike the commonly used additive based attention function (first definition above), this architecture uses the multiplicative attention function rather than computing single attention (weighted sum of values), the “Multi-Head” Attention computes multiple attention weighted sums, hence the name.
Each of these “Multiple-Heads” is a linear transformation of the input representation. This is done so that different parts of the input representations could interact with different parts of the other representation to which it is compared to in the vector space. This provides the model to capture various different aspects of the input and improve its expressive ability.
2.Position-Encoding and Position-Wise Feed Forward NN:
With no recurrence or convolution present, for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence to the embeddings.
The positional encodings have the same dimensions of the embeddings (say, d), so that they can be summed up. Here, 2 sinusoids (sine, cosine functions) of different frequencies are used:
PE(pos,2i) = sin(pos/10000^(2i/d))
PE(pos,2i+1) = cos(pos/10000^(2i/d))
Where pos is the position of the token and i is the dimension.
Encoder:
~ Encoder Input is created by adding the Input Embedding and the Positional Encodings
~ ’N’ layers of Multi-Head Attention and Position-Wise Feed Forward with Residual Connections employed around each of the 2 sub-layers followed by a layer of Normalization
~ Dropouts are also added to the output of each of the above sublayers before it is normalized.
In the encoder phase, the Transformer first generates Initial Inputs (Input Embedding + Position Encoding) for each word in the input sentence. For each word, self-attention aggregates information from all other words (pairwise) in the context of the sentence, thus creating a new representation for each word — which is an attended representation of all other words in the sequence. This is repeated for each word in a sentence successively building newer representations on top of previous ones multiple times.
Decoder:
~ Decoder Input is the Output Embedding + Positional Encoding, which is offset by 1 position to ensure the prediction for position i depends only on the positions before i
~ N layers of Masked Multi-Head Attention, Multi-Head Attention and Position-Wise Feed Forward Network with Residual Connections around them followed by a Layer of Normalization
~ Masked Multi-Head Attention to prevent future words to be part of the attention (at inference time, the decoder would not know about the future outputs)
~ This is followed by Position-Wise Feed Forward NN
The decoder generates one word at a time from left to right. The first word is based on the final representation of the encoder (offset by 1 position) Every word predicted subsequently attends to the previously generated words of the decoder at that layer and the final representation of the encoder (Multi-Head Attention) — similar to a typical encoder-decoder architecture.
BERT (Bidirectional Encoder Representations from Transformers) is a recent paper published by researchers at Google AI Language. It has caused a stir in the Machine Learning community by presenting state-of-the-art results in a wide variety of NLP tasks, including Question Answering (SQuAD v1.1), Natural Language Inference (MNLI), and others. BERT makes use of Transformer, an attention mechanism that learns contextual relations between words (or sub-words) in a text. In its vanilla form, Transformer includes two separate mechanisms — an encoder that reads the text input and a decoder that produces a prediction for the task. Since BERT’s goal is to generate a language model, only the encoder mechanism is necessary. The detailed workings of Transformer are described in a paper by Google. As opposed to directional models, which read the text input sequentially (left-to-right or right-to-left), the Transformer encoder reads the entire sequence of words at once. Therefore it is considered bidirectional, though it would be more accurate to say that it’s non-directional. This characteristic allows the model to learn the context of a word based on all of its surroundings (left and right of the word).
In the BERT training process, the model receives pairs of sentences as input and learns to predict if the second sentence in the pair is the subsequent sentence in the original document. During training, 50% of the inputs are a pair in which the second sentence is the subsequent sentence in the original document, while in the other 50% a random sentence from the corpus is chosen as the second sentence. The assumption is that the random sentence will be disconnected from the first sentence.
To help the model distinguish between the two sentences in training, the input is processed in the following way before entering the model:
~ A [CLS] token is inserted at the beginning of the first sentence and a [SEP] token is inserted at the end of each sentence.
~ A sentence embedding indicating Sentence A or Sentence B is added to each token. Sentence embeddings are similar in concept to token embeddings with a vocabulary of 2.
~ A positional embedding is added to each token to indicate its position in the sequence. The concept and implementation of positional embedding are presented in the Transformer paper.
To predict if the second sentence is indeed connected to the first, the following steps are performed:
->The entire input sequence goes through the Transformer model.
->The output of the [CLS] token is transformed into a 2×1 shaped vector, using a simple classification layer (learned matrices of weights and biases).
->Calculating the probability of IsNextSequence with softmax.
When training the BERT model, Masked LM and Next Sentence Prediction are trained together, with the goal of minimizing the combined loss function of the two strategies.
Here we will make a QnA instance using pre-trained BERT on a dataset given by SquAD.
In this project, we will use Pytorch to serve our purpose
open the project file and run pip install -r requirements.txt
we have a context file in which we can define our context. for example-
in the model directory we have a pre-trained Bert model.
we define a class QnA in which we write our methods for reading questions as well as context text from our context.txt file and then process it through the BERT network and predict the answer as-
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
from __future__ import absolute_import, division, print_function import collections import logging import math import numpy as np import torch from pytorch_transformers import (WEIGHTS_NAME, BertConfig, BertForQuestionAnswering, BertTokenizer) from torch.utils.data import DataLoader, SequentialSampler, TensorDataset from utils import (get_answer, input_to_squad_example, squad_examples_to_features, to_list) RawResult = collections.namedtuple("RawResult", ["unique_id", "start_logits", "end_logits"]) class QA: def __init__(self,model_path: str): self.max_seq_length = 384 self.doc_stride = 128 self.do_lower_case = True self.max_query_length = 64 self.n_best_size = 20 self.max_answer_length = 30 self.model, self.tokenizer = self.load_model(model_path) if torch.cuda.is_available(): self.device = 'cuda' else: self.device = 'cpu' self.model.to(self.device) self.model.eval() def load_model(self,model_path: str,do_lower_case=False): config = BertConfig.from_pretrained(model_path + "/bert_config.json") tokenizer = BertTokenizer.from_pretrained(model_path, do_lower_case=do_lower_case) model = BertForQuestionAnswering.from_pretrained(model_path, from_tf=False, config=config) return model, tokenizer def predict(self,passage :str,question :str): example = input_to_squad_example(passage,question) features = squad_examples_to_features(example,self.tokenizer,self.max_seq_length,self.doc_stride,self.max_query_length) all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long) all_input_mask = torch.tensor([f.input_mask for f in features], dtype=torch.long) all_segment_ids = torch.tensor([f.segment_ids for f in features], dtype=torch.long) all_example_index = torch.arange(all_input_ids.size(0), dtype=torch.long) dataset = TensorDataset(all_input_ids, all_input_mask, all_segment_ids, all_example_index) eval_sampler = SequentialSampler(dataset) eval_dataloader = DataLoader(dataset, sampler=eval_sampler, batch_size=1) all_results = [] for batch in eval_dataloader: batch = tuple(t.to(self.device) for t in batch) with torch.no_grad(): inputs = {'input_ids': batch[0], 'attention_mask': batch[1], 'token_type_ids': batch[2] } example_indices = batch[3] outputs = self.model(**inputs) for i, example_index in enumerate(example_indices): eval_feature = features[example_index.item()] unique_id = int(eval_feature.unique_id) result = RawResult(unique_id = unique_id, start_logits = to_list(outputs[0][i]), end_logits = to_list(outputs[1][i])) all_results.append(result) answer = get_answer(example,features,all_results,self.n_best_size,self.max_answer_length,self.do_lower_case) return answer |
Results:
|
1 2 3 |
model : bert-large-uncased-whole-word-masking {"exact_match": 86.91579943235573, "f1": 93.1532499015869} |
Inference:
|
1 2 3 4 5 6 7 8 9 10 11 |
from bert import QA model = QA('model') doc = open('context.txt', 'r').read() while(True): question = input('Ask a question in context with provided text:') answer = model.predict(doc, question) print('answer:-', answer['answer'], ' ' ,'\n <confidence score:>',f'{answer['confidence']*100}%') |