Recommendation System Using Alternating Least Square
- General
Recommendation System Using Alternating Least Square
Alternating Least Square (ALS) is also a matrix factorization algorithm and it runs itself in a parallel fashion. ALS is implemented in Apache Spark ML and built for a larger-scale collaborative filtering problems. ALS is doing a pretty good job at solving scalability and sparseness of the Ratings data, and it’s simple and scales well to very large datasets.
Some high-level ideas behind ALS are:
Its objective function is slightly different than Funk SVD: ALS uses L2 regularization while Funk uses L1 regularization
Its training routine is different: ALS minimizes two loss functions alternatively; It first holds user matrix fixed and runs gradient descent with item matrix; then it holds item matrix fixed and runs gradient descent with user matrix
Its scalability: ALS runs its gradient descent in parallel across multiple partitions of the underlying training data from a cluster of machines
Just like other machine learning algorithms, ALS has its own set of hyper-parameters. We probably want to tune its hyper-parameters via hold-out validation or cross-validation.
Most important hyper-params in Alternating Least Square (ALS):
maxIter: the maximum number of iterations to run (defaults to 10)
rank: the number of latent factors in the model (defaults to 10)
regParam: the regularization parameter in ALS (defaults to 1.0)
Hyper-parameter tuning is a highly recurring task in many machine learning projects. We can code it up in a function to speed up the tuning iterations.
ALS –
I have worked on Article Recommendation system in which we have data like contentID, personID, eventType, title.
There are different categories for eventType.
Associate each eventType with weight or with strength.
So, I have given eventStrength to eventType like view : 1, like : 2, bookmark : 3, follow : 4, comment created : 5.
In this bookmark on an article indicates a higher interest of the user on that Article than alike.
Now, In this Instead of using or representing explicit rating, that eventStrength can represent a “confidence” in terms of how strong the interaction was.
Articles with large no. of eventStrength can carry more weight in our rating matrix of eventStrengh.
~ Convert into Numeric type codes of person_id and content_id
~ Create 2 matrices -> One for fitting the model (content_id – person_id) Second One for Recommendation (person_id – content_id)
~ Initialize the ALS
~ Fit model using the sparse -> content_id – person_id matrix then, into sparse_content_person
~ I have to set the type of our matrix to double for the ALS function/model to run properly
~ Finding the Similar Articles ? Content_id=450 Top 10 Similar Articles = ?
~ Get person_vectors and content_vectors from our trained model in this person_vectors are model.user_factors which is user matrix and content_vectors are model.item_factors which is item matrix.
~ Calculate the vector_norms
~ Calculate the similarity score
~ And In that matrix with implicit data we can deal with all missing values in our sparse matrix.
Article Recommendation System:-
We are going to use NumPy, pandas, scipy.sparse and implicit for ALS fitting the data.
Data Pre-processing
Remove columns that we do not need.
Remove eventType == 'CONTENT REMOVED' from articles_df.
Merge interactions_df with articles_df.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import pandas as pd import scipy.sparse as sparse import numpy as np import random import implicit from sklearn.preprocessing import MinMaxScaler articles_df = pd.read_csv('shared_articles.csv') interactions_df = pd.read_csv ('users_interactions.csv') articles_df.drop(['authorUserAgent', 'authorRegion', 'authorCountry'], axis=1, inplace=True) interactions_df.drop(['userAgent', 'userRegion', 'userCountry'], axis=1, inplace=True) articles_df = articles_df[articles_df['eventType'] == 'CONTENT SHARED'] articles_df.drop('eventType', axis=1, inplace=True) df = pd.merge(interactions_df[['contentId','personId', 'eventType']], articles_df[['contentId', 'title']], how = 'inner', on = 'contentId') |
This is the data set that will get us to start:
This tells us what event type each person has with each content. There are many duplicated records and we will remove them shortly.
|
1 |
df['eventType'].value_counts() |
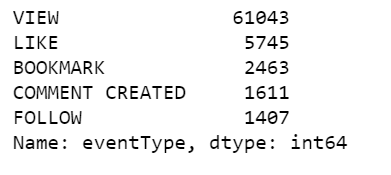
The eventType values are:
VIEW: The user has opened the article. A page view in a content site can mean many things. It can mean that the user is interested, or maybe user is just lost or clicking randomly.
LIKE: The user has liked the article.
BOOKMARK: The user has bookmarked the article for easy return in the future. This is a strong indication that the user finds something of interest.
COMMENT CREATED: The user left a comment on the article.
FOLLOW: The user chose to be notified of any new comment about the article.
We are going to associate each eventType with weight or strength. It is reasonable to assume that for example, a bookmark on an article indicates a higher interest of the user on that article than alike.
|
1 2 3 4 5 6 7 8 |
event_type_strength = { 'VIEW': 1.0, 'LIKE': 2.0, 'BOOKMARK': 3.0, 'FOLLOW': 4.0, 'COMMENT CREATED': 5.0, } df['eventStrength'] = df['eventType'].apply(lambda x: event_type_strength[x]) |
Drop duplicated records.
Group eventStrength together with person and content.
We get the final result of grouped eventStrength.
In this Blog I have assigned weight according to the data, and if we have data like personID, itemID, and more features be like like, view, Add to cart, follow in different columns then first we will calculate the confidence –
We will try to NORMALIZING THEM AND PROVIDING THE RANKS
Like this –
X1, X2, X3 features which are like, view, add to cart
Then, calculate be like this –
NormalizedX1=X1-Mean/Standarddeviation
NormalizedX2=X2-Mean/Standarddeviation
NormalizedX3=X3-Mean/Standarddeviation
After Getting Normalized Features we will try to calculate the Ranks which will be our Confidence/Weight instead of representing an explicit rating.
Alternating Least Squares Recommender Model Fitting:-
Instead of representing an explicit rating, the eventStrength can represent a “confidence” in terms of how strong the interaction was. Articles with a larger number of eventStrength by a person can carry more weight in our ratings matrix of eventStrength.
To get around “negative integer” warning, I will have to create numeric person_id and content_id columns.
Create two matrices, one for fitting the model (content-person) and one for recommendations (person-content).
Initialize the Alternating Least Squares (ALS) recommendation model.
Fit the model using the sparse content-person matrix.
We set the type of our matrix to double for the ALS function to run properly.
|
1 2 3 4 5 6 7 8 9 10 11 |
grouped_df['title'] = grouped_df['title'].astype("category") grouped_df['personId'] = grouped_df['personId'].astype("category") grouped_df['contentId'] = grouped_df['contentId'].astype("category") grouped_df['person_id'] = grouped_df['personId'].cat.codes grouped_df['content_id'] = grouped_df['contentId'].cat.codes sparse_content_person = sparse.csr_matrix((grouped_df['eventStrength'].astype(float),(grouped_df['content_id'], grouped_df['person_id']))) sparse_person_content = sparse.csr_matrix((grouped_df['eventStrength'].astype(float), (grouped_df['person_id'], grouped_df['content_id']))) model = implicit.als.AlternatingLeastSquares(factors=20, regularization=0.1, iterations=50) alpha = 15 data = (sparse_content_person * alpha).astype('double') model.fit(data) |
Finding the Similar Articles :-
-> We are going to find the top 10 most similar articles for content_id = 450
-> Get the person and content vectors from our trained model.
-> Calculate the vector norms.
-> Calculate the similarity score.
-> Get the top 10 contents.
-> Create a list of content-score tuples of most similar articles with this article.
|
1 2 3 4 5 6 7 8 9 10 11 |
content_id = 450 n_similar = 10 person_vecs = model.user_factors #This will be our user vector content_vecs = model.item_factors #This will be our item vector content_norms = np.sqrt((content_vecs * content_vecs).sum(axis=1)) scores = content_vecs.dot(content_vecs[content_id]) / content_norms top_idx = np.argpartition(scores, -n_similar)[-n_similar:] similar = sorted(zip(top_idx, scores[top_idx] / content_norms[content_id]), key=lambda x: -x[1]) for content in similar: idx, score = content print(grouped_df.title.loc[grouped_df.content_id == idx].iloc[0]) |
This will Recommend our Similar Articles That’s how we build a recommendation system, This Approach will be used to build any of the Recommendation systems