MongoDB Sharding
- Digital Engineering
MongoDB Sharding
What is Sharding in MongoDB?
Sharding is a concept in MongoDB, which splits large data sets into small data sets across multiple MongoDB instances.
Sometimes the data within MongoDB will be so huge, that queries against such big data sets can cause a lot of CPU utilization on the server. To handle this situation, MongoDB has a concept of Sharding, which is basically the splitting of data sets across multiple MongoDB instances.
The collection which could be large in size is actually split across multiple collections or Shards as they are called. Logically all the shards work as one collection.
Basics of MongoDB sharding
Clusters are used to implement the shards, Which are the group of MongoDB instances.
The components of a Shard include
A Shard – This is the basic thing, and this is nothing but a MongoDB instance which holds the subset of the data.
Config server – This is a mongodb instance which holds metadata about the cluster, basically information about the various mongodb instances which will hold the shard data.
A Router – This is a mongodb instance which basically is responsible for re-directing the commands sent by the client to the right servers.
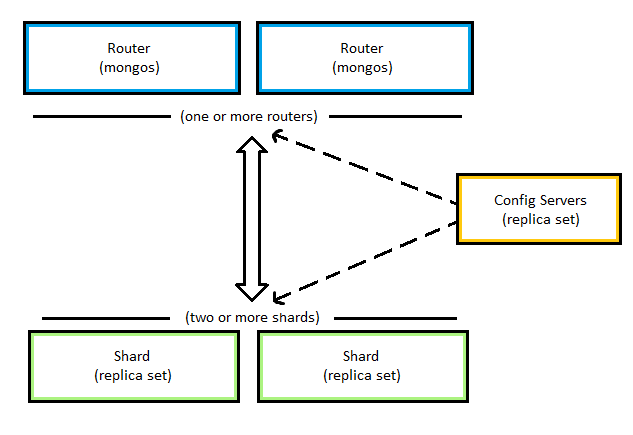
The above diagram from the official MongoDB docs explains the relationship between each component:
- The application communicates with the routers (mongos) about the query to be executed.
- The mongos instance consults the config servers to check which shard contains the required data set to send the query to that shard.
- Finally, the result of the query will be returned to the application.
Shard Keys
When sharding a MongoDB collection, a shard key gets created as one of the initial steps. The “shard key” is used to split the MongoDB collection’s documents across all the shards. The key consists of a single field or multiple fields in every document. The sharded key is immutable and cannot be changed after sharding. A sharded collection only contains a single shard key.
When sharding a populated collection, the collection must have an index that starts with the shard key. For empty collections that don’t have an appropriate index, MongoDB will create an index for the specified shard key.
The shard key can directly have an impact on the performance of the cluster. Hence can lead to bottlenecks in applications associated with the cluster. To mitigate this, before sharding the collection, the shard key must be created based on:
- The schema of the data set
- How the data set is queried
Setup MongoDB Sharding on local ubuntu machine
Now, we understand the concepts of sharding, Lets try to setup it on our local machine (Ununtu 18.04).
- Configure Config Server
We will create one replica set with 3 members as a config server.1mkdir -p /mongodb/csrs/csrs1/db /mongodb/csrs/csrs1/log /mongodb/csrs/csrs2/db /mongodb/csrs/csrs2/log /mongodb/csrs/csrs3/db /mongodb/csrs/csrs3/logWe need to assign a port and set the cluster role as configsvr to mark it as a config server under common replicaSet csrs. So our config file will look like1nano /mongodb/csrs1.confWe will create a config file for the rest of the 2-members of the config replica set. We just need to change ports.12345678910111213sharding:clusterRole: configsvrreplication:replSetName: csrsnet:bindIpAll: trueport: 26001systemLog:destination: filepath: /mongodb/csrs/csrs1/log/csrs1.loglogAppend: truestorage:dbPath: /mongodb/csrs/csrs1/db/
So our csrs2.conf and csrs3.conf are as below
12345678910111213sharding:clusterRole: configsvrreplication:replSetName: csrsnet:bindIpAll: trueport: 26002systemLog:destination: filepath: /mongodb/csrs/csrs2/log/csrs2.loglogAppend: truestorage:dbPath: /mongodb/csrs/csrs2/db/We have created config files. Now we can start 3 mongod instances for each member.12345678910111213sharding:clusterRole: configsvrreplication:replSetName: csrsnet:bindIpAll: trueport: 26002systemLog:destination: filepath: /mongodb/csrs/csrs3/log/csrs3.loglogAppend: truestorage:dbPath: /mongodb/csrs/csrs3/db/
To verify all mongod instances are running by checking logs123mongod -f /mongodb/csrs1.conf&mongod -f /mongodb/csrs2.conf&mongod -f /mongodb/csrs3.conf&
Connect to mongo server on port 26001. Add other 2 as members.123tail -100f /mongodb/csrs/csrs1/log/csrs1.logtail -100f /mongodb/csrs/csrs2/log/csrs2.logtail -100f /mongodb/csrs/csrs3/log/csrs3.log
Note : Here PCNAME is our system name. Please replace it with your system name or host.12345678910mongo --port 26001> rs.initiate()// this will start showing it as primary.// add 2 other config server to the replicaset.> rs.add("PCNAME:26002")// if ip doesn't work use machineName> rs.add("PCNAME:26003")// check all replica set added.> rs.conf()
Now our config server replica set is configured and running.
- Setting up Shards
We will deploy two Shards. Each shard will have a 3 Member replica set.- Setting up Shard-1
Setting up shard replicaset is exactly same what we already did with config replica set. We will just set a clusterRole: shardsvr and we are taking a different replSetName: sh01 that will be common across all the three member’s of same shard replica set.1mkdir -p /mongodb/sh01/sh011/db /mongodb/sh01/sh011/log /mongodb/sh01/sh012/db /mongodb/sh01/sh012/log /mongodb/sh01/sh013/db /mongodb/sh01/sh013/log
We will do the same for the other 2 members. Just create 2 more conf files sh012.conf and sh013.conf. Change the ports to 27012, 27013 and replace the log and db path’s.12345678910111213sharding:clusterRole: shardsvrreplication:replSetName: sh01net:bindIpAll: trueport: 27011systemLog:destination: filepath: /mongodb/sh01/sh011/log/sh011.loglogAppend: truestorage:dbPath: /mongodb/sh01/sh011/db/
Now we will connect to one of them and configure them to be part of the same replica set.123456mongod -f /mongodb/sh011.conf&mongod -f /mongodb/sh012.conf&mongod -f /mongodb/sh013.conf&//Check logs to verify each mongod instance is runningtail -100f /mongodb/sh01/sh011/log/sh011.log
Now we have Shard 01 replica set up and running.12345678mongo --port 27011//Add 2 other members to the replica set.> rs.initiate()> rs.add("PCNAME:27012")> rs.add("PCNAME:27013")// check all replica set added.> rs.conf() - Setting up Shard-2
It’s exactly the same as Shard 01 set-up. Just we have to do find and replace sh01 to sh02 🙂 and assign new port’s for all the configuration and folder structure.Create Server Configuration file sh021.conf, sh022.conf and sh023.conf1mkdir -p /mongodb/sh02/sh021/db /mongodb/sh02/sh021/log /mongodb/sh02/sh022/db /mongodb/sh02/sh022/log /mongodb/sh02/sh023/db /mongodb/sh02/sh023/log
Note :- Copy the same file for other two members and change ports to 27022,27023.12345678910111213sharding:clusterRole: shardsvrreplication:replSetName: sh02net:bindIpAll: trueport: 27021systemLog:destination: filepath: sh02/sh021/log/sh021.loglogAppend: truestorage:dbPath: sh02/sh021/db/
Now we can start the shard server’s. running on port [27021, 27022, 27023]Connect with one mebmber and add other members to make them part of same replica set.123mongod -f /mongodb/sh021.conf&mongod -f /mongodb/sh022.conf&mongod -f /mongodb/sh023.conf&
Now we have Shard 02 replica set up and running.12345678mongo --port 27021> rs.initiate()// add 2 other config server to the replicaset.> rs.add("PCNAME:27022")> rs.add("PCNAME:27023")> rs.status() // check for status, look for Primary/Secondary members.> rs.conf() // see the configuration of replSet.
- Setting up Shard-1
- Configuring Router
Mongo router is a db instance with no database of its own.Create router config file mongos.conf. We will point configDB to our config server. We don’t need a storage section as the router does not have a db of it’s own. Our config file will look like:1mkdir -p /mongodb/router/logNow start the mongos instance using this config and then we connect to our mongos router on port 26000 and add shards to it.123456789sharding:configDB: csrs/PCNAME:26001,PCNAME:26002,PCNAME:26003net:bindIpAll: trueport: 26000systemLog:destination: filepath: /mongodb/router/log/mongos.loglogAppend: trueWe can see our sharded clustered environment is up and running.123456789mongos --config mongos.conf&mongo --port 26000> sh.addShard("sh01/PCNAME:27011")> sh.addShard("sh02/PCNAME:27021")//Check status> sh.status()
All done.. Mongodb sharded Clustered Environment is UP and Running. Hope this was helpful.123456789101112131415161718192021//Connect to mongo routermongo --port 26000//create db booksuse books;//enable shardingsh.enableSharding("books")//create collectiondb.createCollection("author")//create indexdb.author.createIndex( { authorId:1 } )//insert some datadb.author.insertOne({name:"Hitesh Shrimali", authorId : 1})db.author.insertOne({name:"Joe Dow", authorId : 2})db.author.insertOne({name:"Lee Chan", authorId : 3})db.author.insertOne({name:"Rakesh Sharma", authorId : 4})//create shard indexsh.shardCollection("books.author", { authorId : 1} )//check shard distributiondb.author.getShardDistribution()Note – There are three ways we can split data across shard. To start with we can use range or hashed shard. We can also distribute our data based on zone or location. I will try to cover this up in my next blog.